Holo 3.1:来自法国的开源 Agent 模型
这两年,AI Agent 无疑是人工智能领域最热门的方向之一。从 OpenAI 的 Codex 到 Anthropic 的 Claude Code,越来越多的 AI 开始具备自主完成任务的能力。然而,大多数先进的 AI Agent 方案都依赖云端服务,长期使用成本不菲。
最近,来自法国的 AI 公司 H Company 正式发布了 Holo 3.1 Agent 模型。它最大的亮点在于支持本地部署,能够与 OpenClaw 等 Agent 框架对接,让 AI 获得真正的电脑操作能力。最关键的是,Holo 3.1 在各项性能指标上超越了 Qwen 3.5 35B A3B 模型,是当前本地部署 AI Agent 的最佳开源选择。

为什么选择本地 Agent?
本地部署 AI Agent 的核心优势在于:免费无限 Token、数据完全本地化、无需订阅付费、响应速度快。对于需要频繁执行任务的重度用户来说,这意味着一劳永逸地解决成本问题。

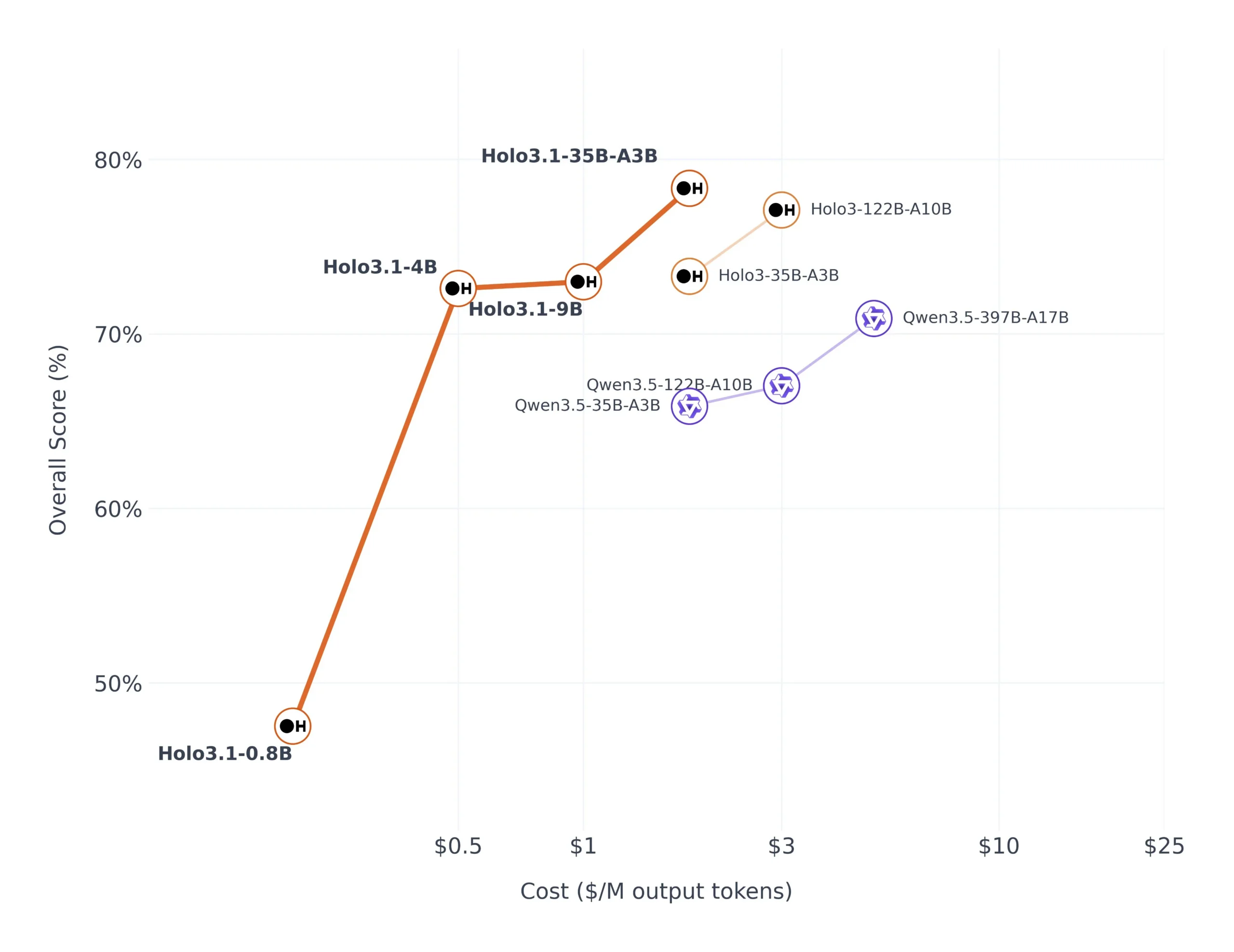
性能对比
Holo 3.1 作为本地 Agent 专用模型,在各项性能指标上都超越了 Qwen 3.5 35B A3B 模型,是本地部署 AI 代理的最佳首选开源模型。
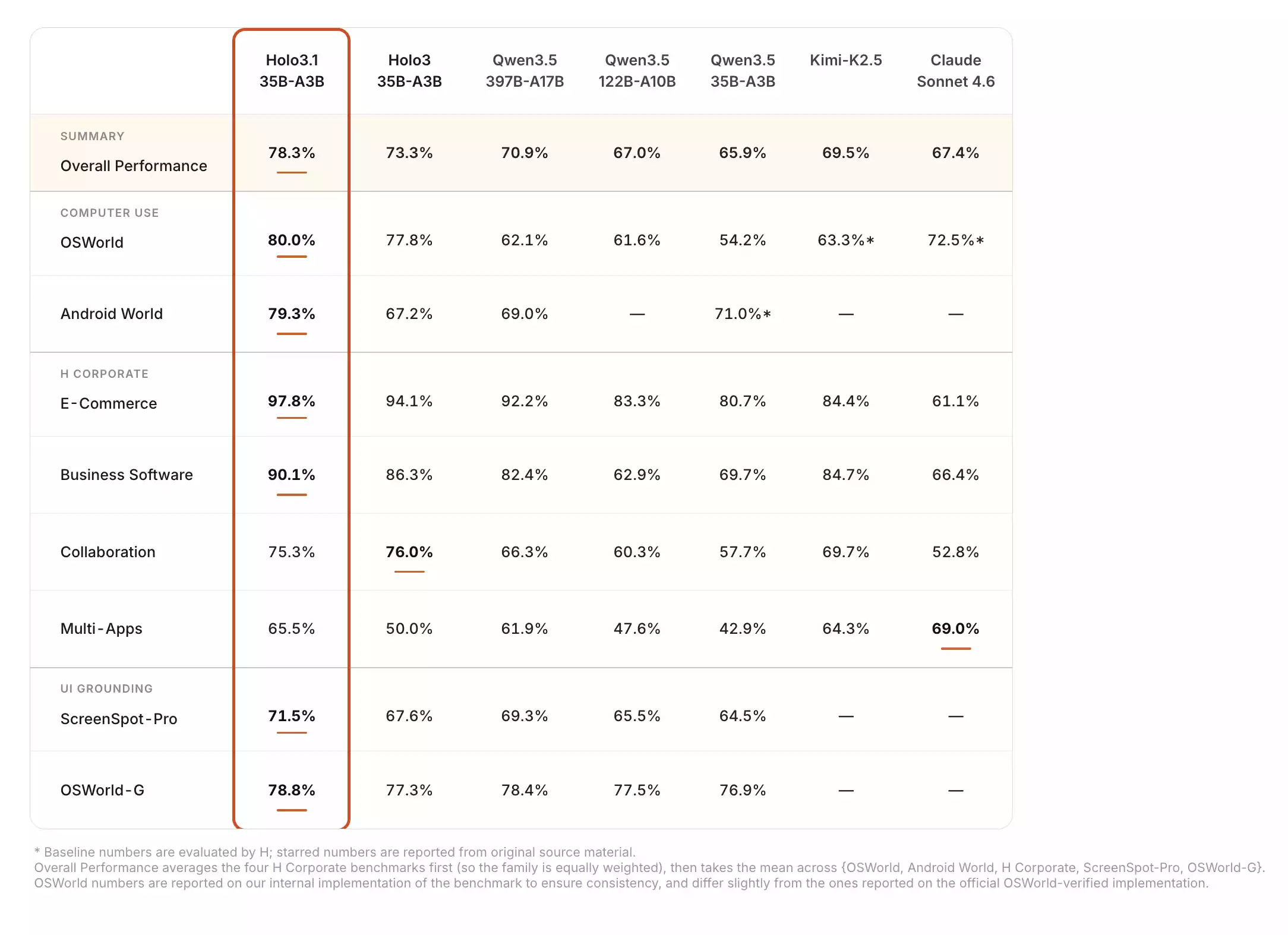
本地部署教程
1. 安装 llama.cpp
本次部署选择 llama.cpp,因为无论是速度还是性能,llama.cpp 都优于 Ollama 和 LM Studio。
| 方案 | 速度 | 易用性 | 适合场景 |
|---|---|---|---|
| llama.cpp | ★★★★★ | ★★★★ | Agent 部署 |
| LM Studio | ★★★★ | ★★★★★ | 日常使用 |
| Ollama | ★★★★ | ★★★★ | API 调用 |
| SGLang | ★★★★★★ | ★ | 极限性能 |
从 GitHub 下载最新版 llama.cpp,解压后在根目录创建 models 文件夹用于存放模型文件。
2. 模型下载
根据显卡配置选择对应的模型:
| 显卡配置 | 推荐模型 |
|---|---|
| RTX 4090/3090 24GB | 35B-A3B Q4_K_M |
| RTX 5070Ti 16GB | 9B |
| RTX 4060Ti 16GB | 9B |
| Apple Silicon | 9B GGUF |
3. 启动脚本
将以下脚本保存为 start.bat,放入 llama.cpp 根目录:
@echo off
chcp 65001 >nul
title Holo 3.1 VLM Launcher
set LLAMA=llama-server.exe
echo ========================
echo Holo 3.1 VLM Launcher
echo ========================
echo 1. 8GB GPU (0.8B)
echo 2. 12GB GPU (4B)
echo 3. 16GB GPU (9B)
echo 4. 24GB GPU (35B-A3B)
echo 5. CPU Mode (4B)
echo 0. Exit
echo.
set /p CH=Select:
if "%CH%"=="1" llama-server.exe -m models\0.8B.gguf -ngl 999 -c 8192 --host 127.0.0.1 --port 1234
if "%CH%"=="2" llama-server.exe -m models\4B.gguf --mmproj models\4B.mmproj -ngl 999 -c 16384 --host 127.0.0.1 --port 1234
if "%CH%"=="3" llama-server.exe -m models\9B.gguf --mmproj models\9B.mmproj -ngl 999 -c 24576 --host 127.0.0.1 --port 1234
if "%CH%"=="4" llama-server.exe -m models\35B.gguf --mmproj models\35B.mmproj -ngl 999 -c 65536 --host 127.0.0.1 --port 1234
if "%CH%"=="5" llama-server.exe -m models\4B.gguf -ngl 0 -c 4096 --host 127.0.0.1 --port 1234
pause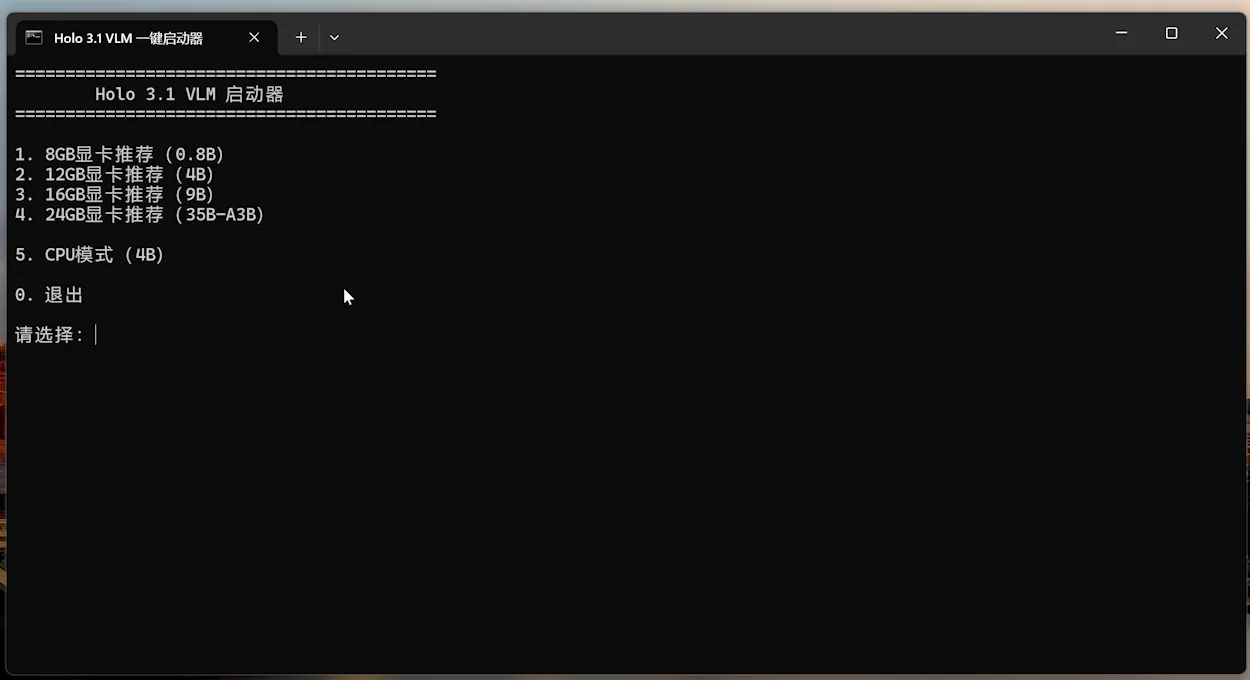
4. 安装 OpenClaw
以管理员身份打开 PowerShell,执行一键安装命令:
powershell -c "irm https://openclaw.ai/install.ps1 | iex"安装后在模型提供商设置中,将 API Base URL 填写为:
http://127.0.0.1:1234/v1密钥留空即可。
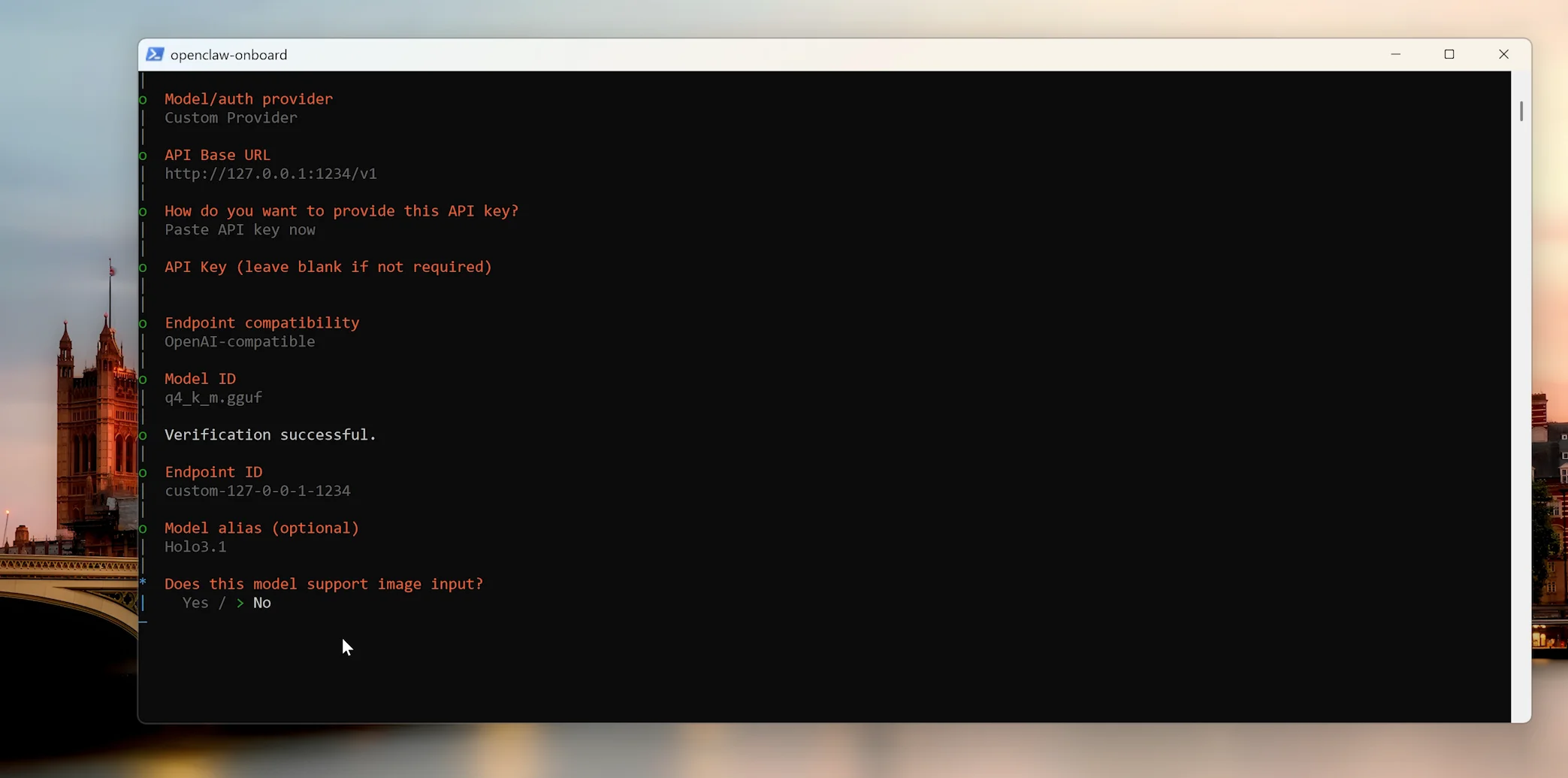
5. 安装浏览器自动化 Skills
启动 OpenClaw 后,安装必备的浏览器自动化插件:
openclaw skills install agent-browser-cli
openclaw skills install use-my-browser
openclaw gateway安装完成后,AI Agent 即可像真人一样操作浏览器、搜索资料、整理信息并完成复杂任务。
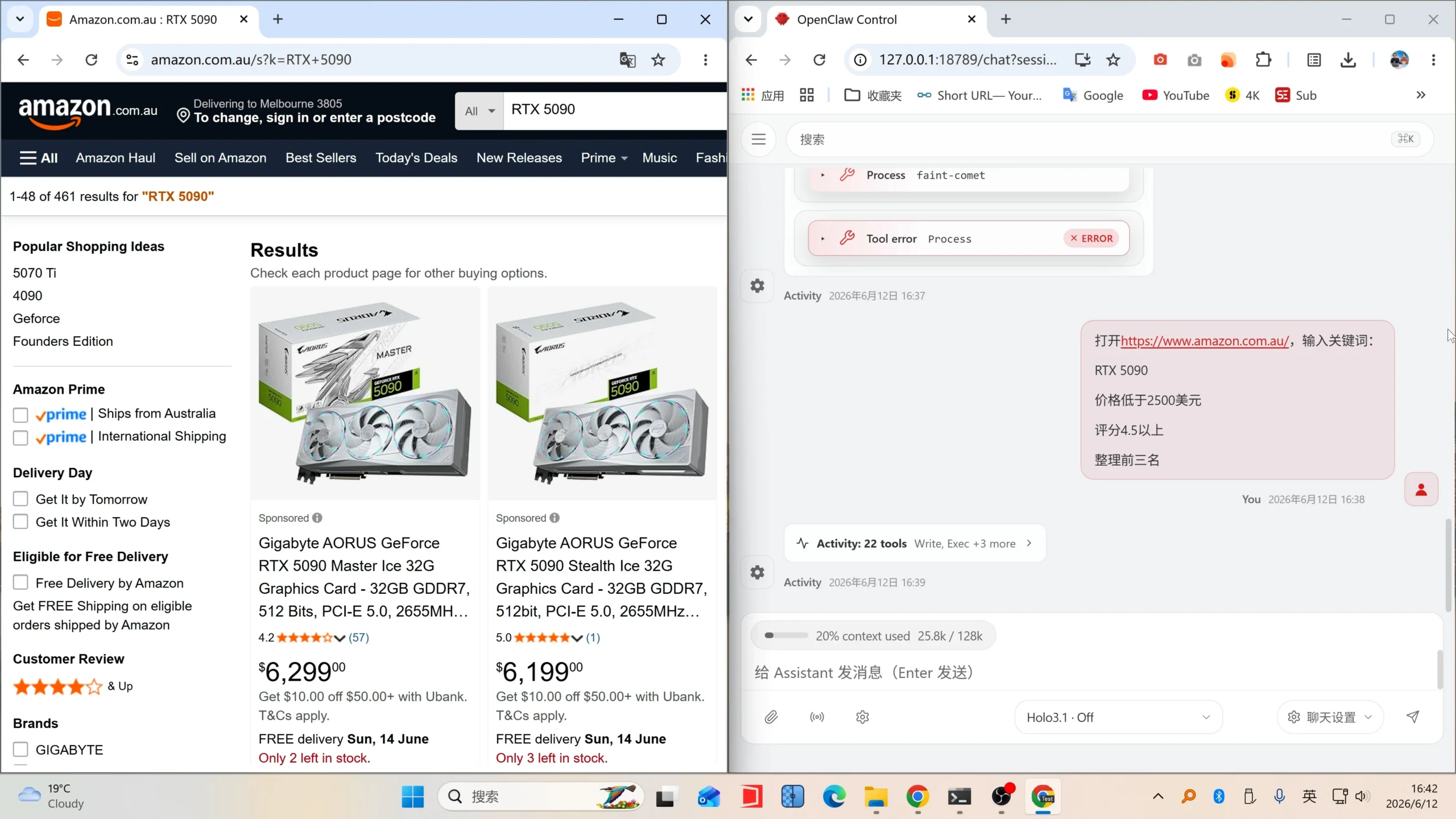
实测体验
经过实际测试,Holo 3.1 在 OpenClaw 下的表现令人惊喜。浏览器自动化操作非常流畅,速度比之前的 Qwen 3.5 模型快了很多倍。本地模型执行 AI Agent 任务几乎不需要等待,响应迅速。
只需一张性能不错的独立显卡,你就可以完全替代付费的 API 服务。如果你的任务不是特别复杂且不需要高难度推理,那么 Holo 3.1 就是最佳的本地部署方案——真正完全免费、无需 Token、无需绑定任何付费套餐。