Google Gemma 4 12B 本地部署实测:支持音频输入,12B 参数挑战更大模型
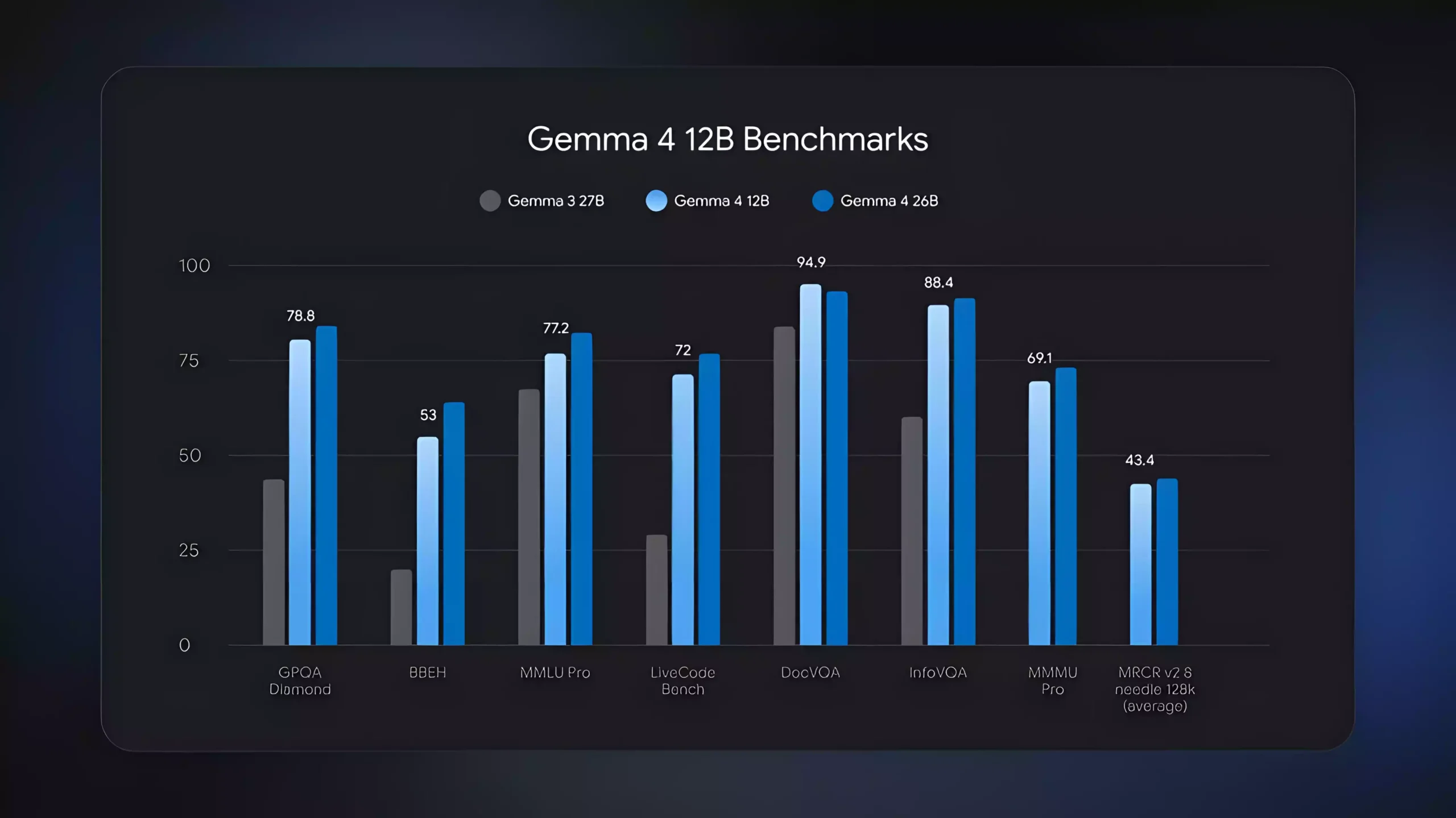
Google 最近正式发布了 Gemma 4 12B,这是 Gemma 系列最新的开放权重模型。相比上一代,Gemma 4 不仅拥有更强的推理能力,还加入了多模态支持,可处理文本、图片甚至音频内容。

对于喜欢本地部署 AI 的用户来说,Gemma 4 12B 最大的吸引力在于:仅 120 亿参数、支持消费级显卡运行、支持多模态输入、支持超长上下文,可通过 llama.cpp 本地部署。
Gemma 4 12B 核心亮点
多模态支持
Gemma 4 不仅支持文本输入,还支持图片理解、音频理解与多模态推理。可用于分析截图、理解照片内容、总结音频以及视频语音理解等场景。
超长上下文
官方支持最高 256K Context,这意味着超长 PDF、整本电子书、大型代码项目都可以一次性进行分析。
本地运行门槛低
即使是 RTX 3060 12GB 这样的主流显卡,也能运行 Gemma 4 12B 的量化版本。
| 显存 | 推荐模型 |
|---|---|
| 8GB | IQ2_XS |
| 12GB | Q4_K_M |
| 16GB | Q6_K |
| 24GB | Q8_0 |
本地部署教程
1. 下载模型
从 HuggingFace 下载主模型和视觉模型。显存较小的用户可选择 Unsloth 提供的更多量化版本。
2. 安装 llama.cpp
从 GitHub 下载最新版 llama.cpp,解压后在根目录创建 models 文件夹,将模型文件放入其中。
3. 启动脚本
以下启动脚本支持按显存配置选择对应模式:
@echo off
chcp 65001 >nul
title Gemma 4 Launcher
echo ==============================
echo Gemma 4 Smart Launcher
echo ==============================
echo 1. 6GB VRAM (4B Q4)
echo 2. 8GB VRAM (12B IQ2)
echo 3. 12GB VRAM (12B Q4)
echo 4. 16GB VRAM (12B Q6)
echo 5. 24GB VRAM (12B Q8)
echo 6. 12GB + Vision
echo 7. 16GB + Vision
echo 8. 24GB + Vision
echo 9. BF16 Vision (4090)
echo 0. Exit
echo.
set /p ch=Select:
if "%ch%"=="1" llama-server -m models\gemma-4-4B-it-Q4_K_M.gguf -ngl 999 -c 8192 --host 127.0.0.1
if "%ch%"=="2" llama-server -m models\gemma-4-12B-it-IQ2_XS.gguf -ngl 999 -c 8192 --host 127.0.0.1
if "%ch%"=="3" llama-server -m models\gemma-4-12B-it-Q4_K_M.gguf -ngl 999 -c 32768 --host 127.0.0.1
if "%ch%"=="4" llama-server -m models\gemma-4-12B-it-Q6_K.gguf -ngl 999 -c 32768 --host 127.0.0.1
if "%ch%"=="5" llama-server -m models\gemma-4-12B-it-Q8_0.gguf -ngl 999 -c 65536 --host 127.0.0.1
if "%ch%"=="6" llama-server -m models\gemma-4-12B-it-Q4_K_M.gguf --mmproj models\mmproj-Q8_0.gguf -ngl 999 -c 32768 --host 127.0.0.1
if "%ch%"=="7" llama-server -m models\gemma-4-12B-it-Q6_K.gguf --mmproj models\mmproj-F16.gguf -ngl 999 -c 32768 --host 127.0.0.1
if "%ch%"=="8" llama-server -m models\gemma-4-12B-it-Q8_0.gguf --mmproj models\mmproj-Q8_0.gguf -ngl 999 -c 65536 --host 127.0.0.1
pause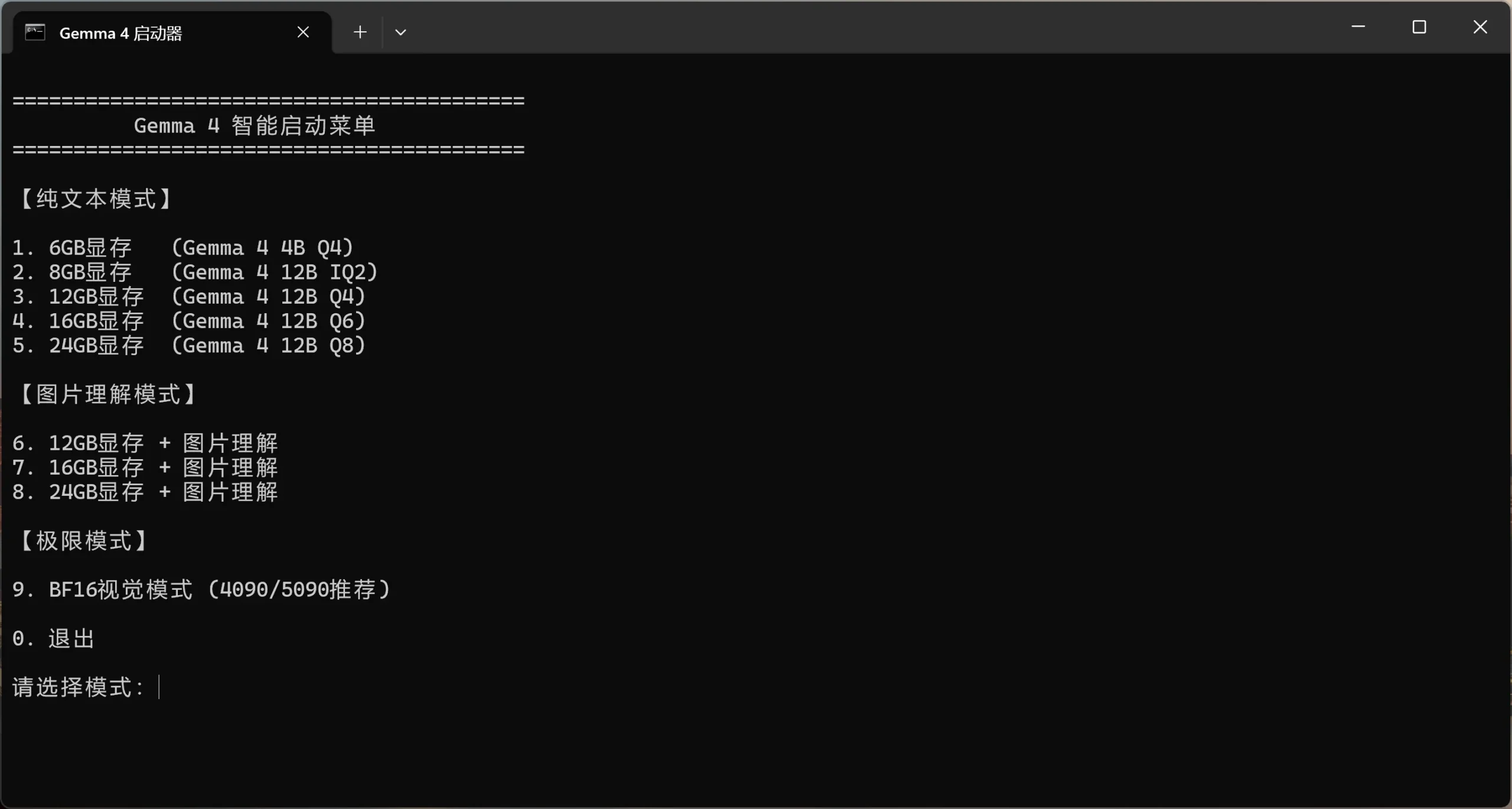
实测总结
Gemma 4 12B 最大的价值并不是参数数量,而是在模型体积与能力之间取得了不错的平衡。它同时具备文本推理、编程能力、图片理解、音频理解和超长上下文能力。
对于拥有 RTX 3060、4060Ti、4070、4090 等显卡的用户来说,Gemma 4 12B 是一个非常值得体验的本地 AI 模型。